

AO is about to be released: Can Arweave regain momentum?

Original article: ArringtonCapital
Compiled by: Yuliya, PANews
On February 8, 2025, the AO mainnet will be launched, which is an important milestone for the AI and cryptocurrency communities. AO aims to provide a highly parallel computing layer for proxy applications, and Arweave, the permanent data storage network behind it, plays a key role in this. This article will deeply analyze Arweave's permanent storage architecture, AO's hyper-parallel computing model, and how the two will drive the future development of on-chain autonomous agents. At the same time, it will also explore the challenges faced by AR and AO, market dynamics, and how to participate in them.
Arweave Overview
Arweave is a decentralized permanent data storage network. Users only need to pay a one-time storage fee to obtain permanent data storage services. Unlike other storage networks (such as Filecoin) that require continuous payment, Arweave uses a unique block structure called "blockweave". Each new block is not only linked to the previous block, but also randomly linked to earlier historical blocks, ensuring that miners must hold complete historical data to generate new blocks, thereby achieving long-term data preservation.
Arweave's native token AR is used to pay for storage and reward miners. When users upload new data and pay fees, about 85% of the tokens are deposited into a fund for future miner rewards. This design ensures that miners' incentives are independent of user activity and enhances confidence in the permanent storage of data.
Growth trajectory
Since launching in June 2018, Arweave usage has grown significantly in 2021. The following chart tracks weekly data uploads since the network launch:
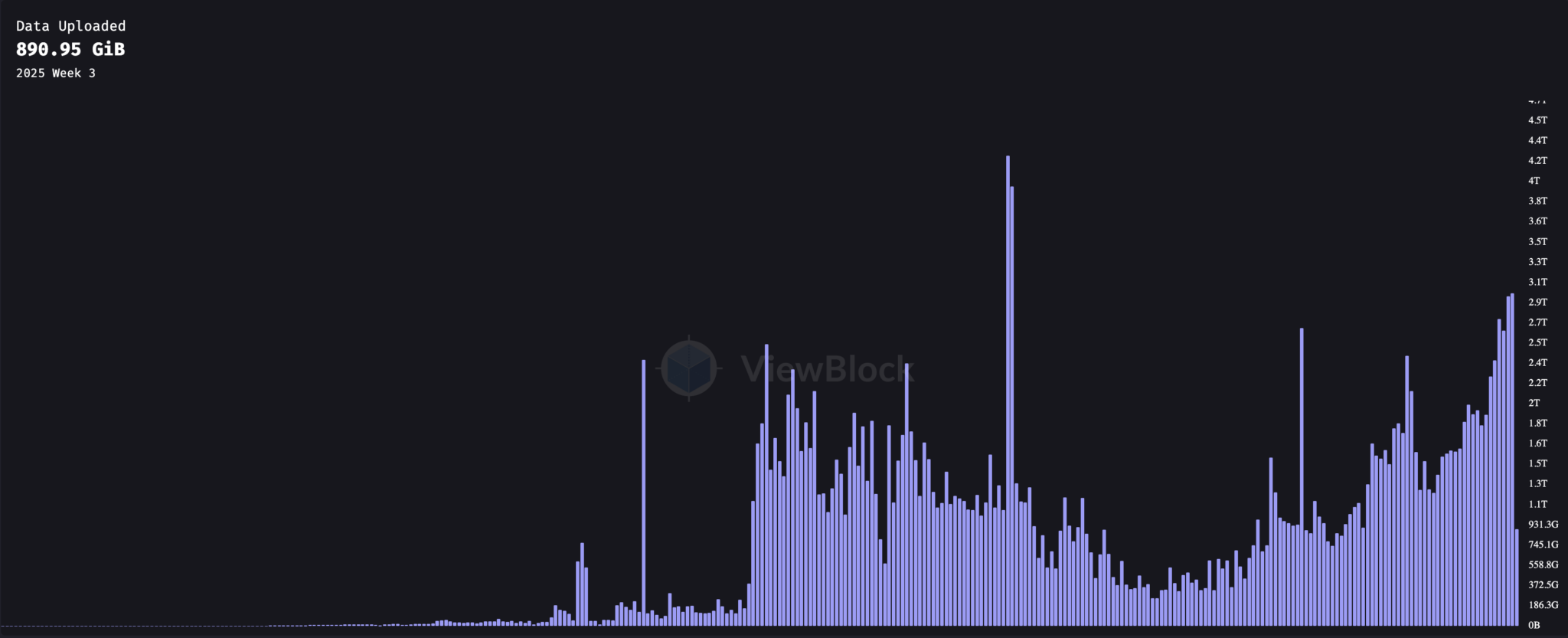
Data storage peaked in September 2021, bottomed out in June 2023, and has been climbing steadily since then. The chart below breaks down the type of data uploaded each month.
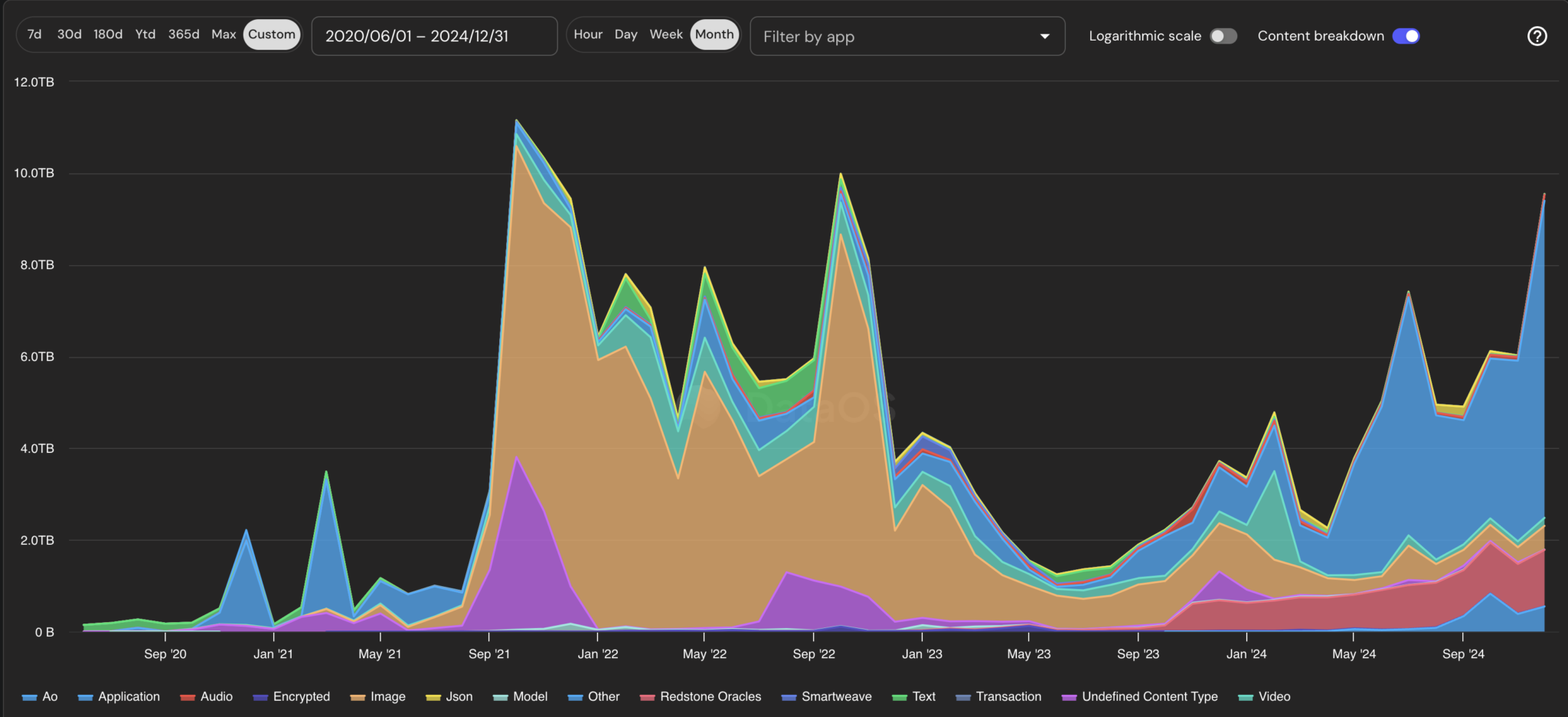
Arweave usage over time (by size)
In 2021, the rise of NFTs drove the first major increase in demand for Arweave data storage. Creators began uploading JPEGs and images to Arweave instead of relying on centralized hosting services, a trend that has led to a surge in Arweave usage. Due to its permanent and decentralized nature, Arweave has become an ideal choice for NFT artwork data storage.
Since 2023, a range of new use cases have emerged. Of all the categories, applications take up the most storage space. These are mainly packager applications that package multiple transactions and data together and publish them to Arweave. These include Bundlr (the team has changed its name to Irys.xyz and will launch its own data chain in addition to the packager application) and Ardrive Turbo . The data packaged by these applications includes content that may have previously been classified as pictures, videos, or other blockchain data. In addition to these packager applications, there are other projects that are taking advantage of Arweave's permanent storage capabilities, including Lens' social application Hey , content publishing platform Mirror , and AI application scenario Ritual .
Judging from the number of transactions, although Arweave charges fees based on the size of the stored data, the growing number of transactions may indicate the future development direction of Arweave.
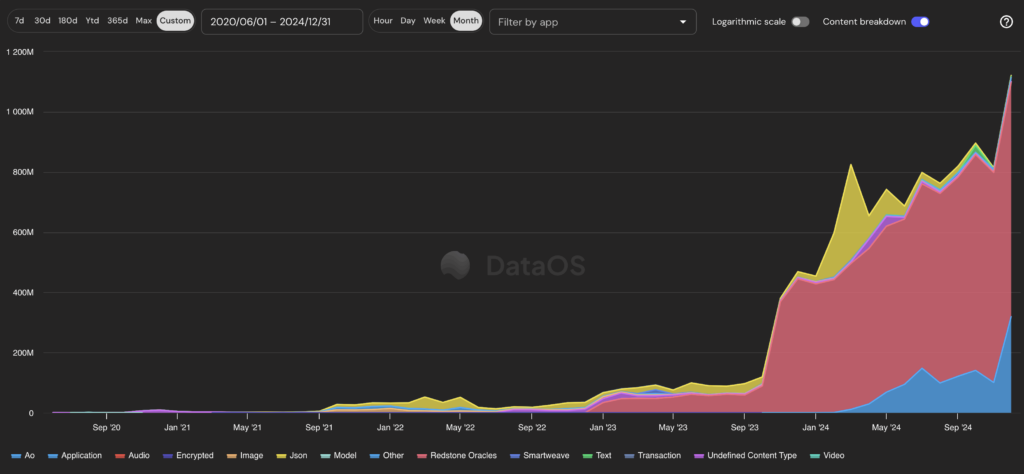
Arweave usage over time (by number of transactions)
Transaction volume data shows that the two fastest growing use cases in the blockchain ecosystem are Redstone and AO .
- Redstone
Redstone is one of the fastest growing oracle networks in the crypto space, providing price data for multiple assets across all major EVM chains. The network’s rapid growth is due to its expanding partnerships and product features.
- AO
AO is a parallel computing and proxy messaging layer built on Arweave. Although it is still in the testnet stage, its mainnet is scheduled to be launched in February 2025. AO is designed to provide efficient computing infrastructure for proxy applications and use Arweave's permanent storage capabilities to support on-chain autonomous agents.
Criticisms of Arweave
Although Arweave’s storage model has been recognized, it has also faced some criticism, especially its low fee income. The following is a comparison of the PE ratios of different blockchains:
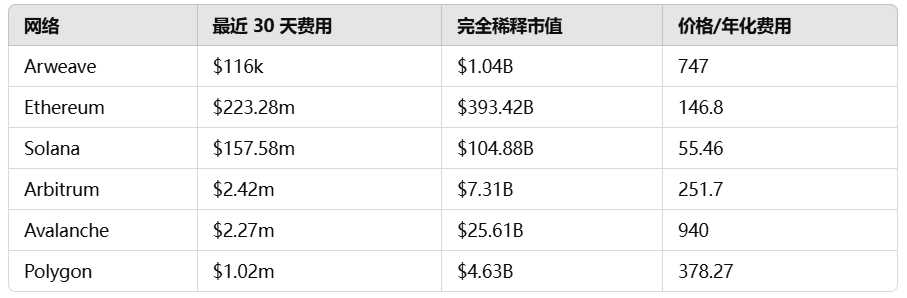
Looking at the price/fee ratio, Arweave outperforms only Avalanche among L1 chains. A lower ratio indicates that users pay higher fees relative to the fully diluted value (FDV) of the network. These figures reflect the total fees generated but do not take into account miner payments or Arweave's endowment fund contributions. Because Arweave allocates a larger portion of fees to miners, its short-term profits may appear smaller than other chains.
AR Token Performance
In 2024, AR saw significant growth after the announcement of the AO project. After the announcement, the price of Arweave tokens soared from less than $10 per token to more than $40. The market showed strong interest in the possibilities that AO brought to cryptocurrencies and the expected growth in Arweave activity.
AR holders can accumulate AO tokens by holding AR in their wallets starting in February 2024. Currently, 33% of newly created AO is in circulation to holders, and these tokens will be available for transfer when the AO mainnet is launched in February 2025.
After the mainnet launch, AR holders will continue to receive one-third of the AO token issuance until the creation cap of 2.1 million AO tokens is reached. These rewards are calculated every five minutes at a monthly rate of 1.425% of the remaining supply, meaning that token issuance will decrease over time.
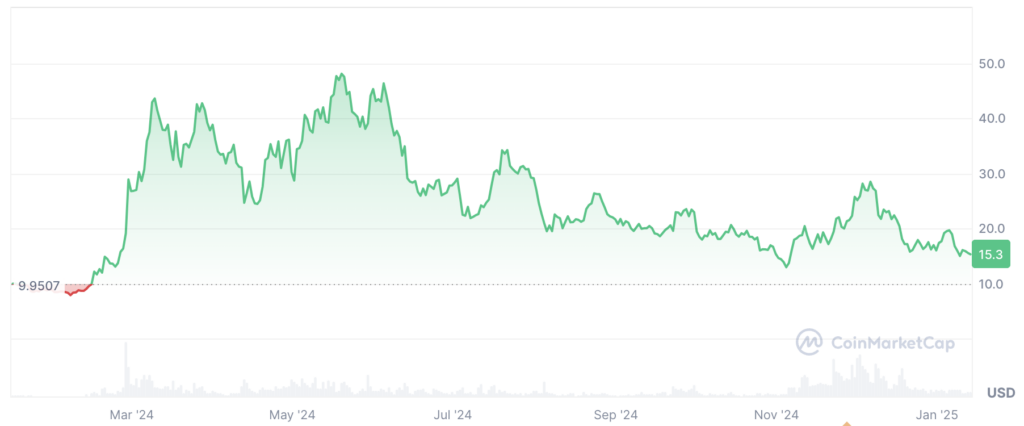
AR Price (USD)
As the overall market fell, AR's price also fell in the summer. Compared with tokens with AI value attributes such as RENDER, TAO, and NEAR, AR's performance is relatively lagging. On-chain capital flow may be an important factor in this phenomenon.
Since September 2024, the market has observed a large number of AR tokens being sold by a large investor. The identity of this investor has not been confirmed, although there are clues. The wallet address dRFuVE-s6-TgmykU4Zqn246AR2PIsf3HhBhZ0t5-WXE received more than 10 million AR tokens in November 2021 (the total supply of AR is less than 66 million). The wallet had transfer records before 2023 and still held 5 million tokens in 2024 (about $80 million at the current price of $16).
On September 6, the wallet moved the remaining 5 million tokens to two new addresses. These addresses subsequently transferred the tokens to exchanges, indicating that these may be market maker addresses. Of the 5 million tokens, approximately 1.35 million tokens remain in addresses presumably belonging to market makers, waiting to be transferred to exchanges.
The transfer of funds from two addresses to the same destination address of the exchange indicates that this is likely to be operated by the same market maker. This wave of selling pressure accounts for a large proportion of the circulating supply, exceeding 7% of the total AR tokens. Market analysis believes that once the remaining tokens are sold, the downward pressure on the AR market may be alleviated.
AO Overview
AO is a decentralized "hyper-parallelized" network that breaks through the traditional limitations of on-chain computing scale and type while maintaining the verifiability of all operations. The core of AO is a messaging layer that supports independent and parallel processes and uses Arweave to provide permanent data storage, ensuring that all updates and interactions are permanently recorded.
"AO" stands for "Actor Oriented". Developers can build modular programs (actors). Each actor can choose its own virtual machine (VM), consensus mechanism and payment model, and communicate with other actors through standardized message formats. This design allows cloud applications (such as Amazon EC2) to access AO's decentralized network and collaborate with decentralized smart contracts to achieve common goals.
AO Features
- Existing applications
Some AO agents are already in use. For example, one agent can continuously optimize the returns of crypto assets across multiple lending protocols; another agent can automatically execute fixed investment strategies on DEX based on user-defined parameters. These agents use trusted execution environments (TEEs) to protect user privacy and allow users to host private keys, thereby achieving full autonomy without the need for additional instructions.
- Automatic wake-up function
Unlike other Layer1s, AO programs can "wake up" autonomously without external calls. This design supports fully autonomous services. For example, the yield optimization agent can reallocate assets to higher-yield strategies while users are sleeping, without manual triggering.
AO Architecture
1. Processes:
A process is equivalent to a single "actor" on an AO, starting from an initial state and recording all received messages. Data is stored on Arweave, ensuring that it cannot be lost or censored. By separating data recording from actual computation, AO can handle larger tasks than a typical blockchain.
2. Messages:
Messages are the way processes and users interact, and are sent over the network with unique IDs for easy tracking. Message delivery must be correct to be delivered, which provides flexibility in flow control while ensuring that messages are permanently recorded.
3. Scheduler Units:
The scheduling unit adds incremental time slot numbers to messages and ensures that they are uploaded to Arweave, maintaining a consistent record of message sequences. It can be centralized or decentralized depending on the use case requirements.
4. Compute Units:
Computing units are responsible for the actual running of the process and can freely choose the process to be computed, forming a competitive market for computing services. After completing the work, they will return a signed proof of the process state change.
5. Messenger Units:
The message passing unit is responsible for message transmission in the network, ensuring that the message is recorded on Arweave by the scheduling unit and then passed to the computing unit until all operations are completed.
Challenges facing AO
The AO project faces some important challenges. Every network will eventually need to establish advantages in one or two verticals. For example, Arbitrum focuses on DeFi, Solana excels in Meme coins and DePIN, and IMX focuses on games. Arweave has been focusing on content storage, blockchain archiving, and oracle data permanence. AO is trying to redefine decentralized content and DeFi, especially in promoting the application of AI agents in the DeFi field.
1. DeFi adoption challenges
Although AO is committed to promoting the integration of DeFi and AI, the adoption of AI agents in the DeFi field has been slow, and no breakthrough applications have yet emerged. The closest attempt is to introduce machine learning models on-chain for yield optimization. However, these models are usually simple and are mainly used for yield prediction and strategy switching cost comparison. In contrast, large language models are highly nonlinear and non-deterministic, and still have difficulties in basic calculations.
2. Background of non-DeFi chains
Arweave is not a traditional DeFi public chain, and previous attempts to build DEX on it have failed. Therefore, AO needs to attract Arweave's existing community and new user groups. The token economics designed by the team reflects a deep understanding of this challenge, such as rewarding users who bridge DAI and stETH to attract funds. At present, AO's TVL has reached 578 million US dollars, and how to maintain the activity of these capitals is the key.
Token Economy and Participation Methods
After the mainnet launch in February 2025, anyone can contribute computing resources or deploy their own processes and agents. Cross-chain bridges will be open to support the transfer of any token to the AO network. As more people join and develop advanced AI or automated services, AO's decentralized and efficient architecture will unlock new possibilities in areas of trust and high computing power requirements.
Airdrop Mechanism
- Total token supply and release plan: The total supply of AO tokens is 21 million, which will be halved at set intervals.
- Airdrop qualifications: AR holders will receive AO airdrops according to their holding ratio; users who bridge DAI and stETH can also receive allocations.
- Distribution method: Since February 27, 2024, 1.03 million AO tokens have been distributed to holders and bridgers; AR holdings are counted every 5 minutes to calculate the distribution ratio.
How to participate
- Holding AR Tokens : One-third of the newly issued AO tokens are allocated to AR holders
- Cross-chain transfer to DAI or stETH : Currently two-thirds of AO tokens are allocated to cross-chain users
- Use AO mainnet application : multiple trading and lending platforms will be provided after the mainnet is launched
- Providing computing resources : Anyone can contribute computing power to various processes on AO without permission
*Disclaimer: The author Arrington Capital is an early investor in Arweave and holds AR and AO tokens.
You May Also Like

Ethereum unveils roadmap focusing on scaling, interoperability, and security at Japan Dev Conference

Here’s How Consumers May Benefit From Lower Interest Rates
