

Multi-Task vs. Single-Task ICR: Quantifying the High Sensitivity to Distractor Facts in Reasoning
Table of Links
Abstract and 1. Introduction
-
Background
-
Method
-
Experiments
4.1 Multi-hop Reasoning Performance
4.2 Reasoning with Distractors
4.3 Generalization to Real-World knowledge
4.4 Run-time Analysis
4.5 Memorizing Knowledge
-
Related Work
-
Conclusion, Acknowledgements, and References
\ A. Dataset
B. In-context Reasoning with Distractors
C. Implementation Details
D. Adaptive Learning Rate
E. Experiments with Large Language Models
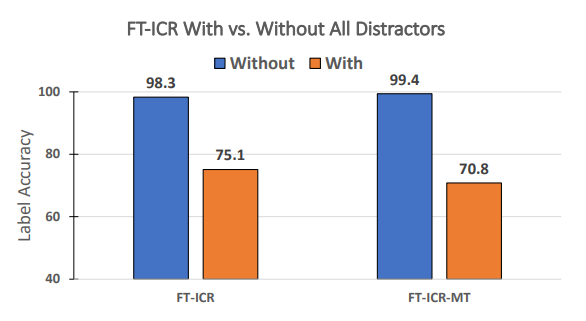
B In-context Reasoning with Distractors
To motivate the advantage of RECKONING on mitigating interference from distractors, we analyze the performance change of fine-tuned incontext reasoning with and without distractors present in the context of the questions. We define distractors as additional facts or rules present in a question’s context that are not directly relevant to the questions. A model should not be able to use only these distractors to answer a question correctly. For an example of distractors in a question’s context, please see Table 9. We evaluate the baseline on the ProofWriter dataset since it naturally contains contexts including distractors (Table 9). Recall that we have two training objectives. The single-task objective only trains the model to predict an answer for each question given their contexts. The multi-task objective (MT) trains the model not only to predict an answer but also to reproduce the correct facts and rules (in contrast to distractors) based on the contexts. We evaluate the baseline on 2, 3, and 5-hop datasets with both training objectives, and we report the average label accuracy across hops in Figure 7. Compared to the baseline’s performance without distractors in the context, the performance with distractors decreases significantly. For single-task, the performance drops 23.2% when adding distractors to the contexts, and the performance with the multi-task objective drops 28.6%. The results highlight in-context reasoning’s high sensitivity to the interference of irrelevant information in the contexts.
\ 
\
:::info Authors:
(1) Zeming Chen, EPFL (zeming.chen@epfl.ch);
(2) Gail Weiss, EPFL (antoine.bosselut@epfl.ch);
(3) Eric Mitchell, Stanford University (eric.mitchell@cs.stanford.edu)';
(4) Asli Celikyilmaz, Meta AI Research (aslic@meta.com);
(5) Antoine Bosselut, EPFL (antoine.bosselut@epfl.ch).
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
You May Also Like

Latest Ripple News As CEO Says XRP ETFs Inevitable By 2026 and XRP Price Prediction

Yesterday, the whale who shorted ASTER with 3x leverage added 2.3 million USDC margin.
