

Поиск решений управляемый данными. Детали механизма
В предыдущих статьях цикла были рассмотрены информационные блоки и словарь, являющиеся фундаментом технологии поиска решений управляемого данными. Ключевая особенность технологии – динамическое построение алгоритмов из самодостаточных фрагментов формализованной предметной информации. В этой статье будут детально рассмотрены механизмы, управляющие процессом динамического связывания информационных блоков для достижения конечной цели – получения грамотно обоснованного прикладного решения.
Ниже приведено техническое описание основных деталей алгоритма поиска решений управляемого данными. В конце статьи приведены блок-схема и псевдокод возможной программной реализации этой информационной технологии.
Важно отметить, что изложение не привязано к каким-то конкретным математическим методам и технологическим решениям работы с данными: Марковский подход, RL (reinforcement learning), простая статистика частот, ML‑модели, ….
Примеры будут носить абстрактный характер. Детальный разбор перегрузит изложение и уведёт в сторону от основных идей.
Понятийный аппарат
На рисунке ниже представлены условные изображения информационных блоков и параметров задачи.

Простой механизм поиска решений
В простейшем варианте организации базы знаний информационные блоки никак не связаны между собой. Это чем-то напоминает "суп" из фрагментов органических соединений породивший все формы жизни на земле. Чтобы из информационных блоков сложилась последовательность, приводящая к результату – надо указать, что искать, и, возможно, сразу задать набор исходных данных.

Если исходные данные (рис. 2, параметры 4,7,12,13) не задать заранее, они будут запрашиваться в диалоге по мере необходимости.
Выполняется поиск информационных блоков (рис. 2, б), в которых может быть определён выходной параметр (рис.2, в, параметр 31). Информационные блоки проверяются на возможность своего выполнения. Если данных для выполнения достаточно и их значения укладываются в ограничения на входные параметры – информационный блок (применяется) выполняется. Решение найдено (рис. 2, в, параметр 31).
Основная идея представления предметных знаний информационными блоками – свободное фрагментирование и формализация информации. Свободное фрагментирование подразумевает получение схожих сведений из разных источников. Такие сведения могут значительно отличаться полнотой и истинностью. Соответственно, для определения одного и того же выходного параметра могут быть использованы разные информационные блоки. Например, на рис. 2 все блоки могут подойти для определения параметра 31. Однако наборы входных параметров отличаются:
-
Блоки идентичны по набору входных параметров (рис. 2, блоки В1 и В4).
-
Блоки отличаются наборами входных параметров, которые пересекаются только частично и, количество входных параметров различно (рис. 2, блоки В1, В2, В5, В6).
-
Блоки отличаются наборами входных параметров, которые не пересекаются (рис.2, блок В3 по набору входных параметров не пересекается ни с одним из других блоков).
Предварительный визуальный анализ информационных блоков позволяет заранее выявить и устранить проблемы за счёт корректировки информационного наполнения. Тем не менее, даже если такого анализа не было, процесс поиска всё равно можно продолжать. Разумно предположить, что информационный блок с наибольшим количеством входных параметров обеспечит наиболее правдоподобный и обоснованный результат (рис. 2, блок В6). Это укладывается в парадигму, где прикладные задачи реализуют сами узкие специалисты предметной области. Участие ИТ‑специалистов при этом минимально. Высока вероятность, что, оценивая результаты поиска решений и используя подсказки нейросетевых моделей, прикладные специалисты смогут самостоятельно привести в порядок информационное наполнение.
В соответствии с вышеизложенным блок В2 (рис. 2) может дать худший результат, чем блок В6. Но для выполнения блока В6 не хватило заранее заданных входных параметров, а для блока В2 данных достаточно. Для других блоков количество известных параметров избыточно.
Параметры, которых не хватило, станут промежуточными. Например, параметр 20 (см. рис. 2) может стать промежуточным. Для каждого промежуточного параметра необходим поиск, подходящих для его определения, информационных блоков.
Очевидно, что параметры не однозначны по своему влиянию на выбор направления поиска (определения последовательности отбора блоков для выполнения).

В первую очередь следует попытаться определить параметры, которые выше в иерархии терминологического словаря. Такими параметрами (рис. 3) будут 5 и 6. Чтобы их найти, надо узнать параметры 1, 2 и 4.
Таким образом, очередь параметров требующих определения будет подрастать с каждым шагом отбора блоков для выполнения. Соответственно, будет увеличиваться количество информации. Количество информации - условная величина. Её изменение сигнализирует, что процесс поиска решений не зашел в тупик. Процесс отбора блоков для выполнения иллюстрируется схемой (рис. 4).

Если на очередном шаге удастся выполнить блок, ожидавший в очереди на выполнение (рис. 4, в, шаг 5), изменится контекст задачи (увеличится количество известных параметров).
В идеале, из очереди должен выполниться блок, определяющий наиболее важный и значимый параметр. На практике может оказаться, что выполнится другой блок, для которого уже достаточно накопленной информации. Это подходящая работа для вероятностной модели: проанализировать блоки на правильность их позиционирования в очереди и подсказать, как следует подкорректировать информационное выполнение. Правильность информационных блоков во многом зависит от качества исходных материалов и квалификации прикладных специалистов.
Так или иначе, но процесс поиска продолжится и, если данных будет накоплено достаточно, то с высокой степенью вероятности решение найдётся.
Может случиться так, что на очередном шаге количество информации не изменится. Здесь возможны варианты:
-
Блоки для определения параметров имеются, но ни один не подошёл по условиям применимости. Это означает, что надо дополнять базу знаний.
-
Нет блоков для определения промежуточного параметра. Это означает, что данный параметр должен стать входным (заданным). Или надо дополнить базу знаний соответствующими информационными блоками. В частности, можно попытаться использовать для этого известные на текущий момент параметры.
И в том и в другом случае, чтобы не прерывать поиск решений, может помочь диалоговый ввод недостающих параметров.
Динамическое формирование областей допустимых значений
По мере движения к цели уточняется контекст задачи. Это влияет на изменение состава подходящих по контексту информационных блоков. Появляются дополнительные ограничения на ввод значений недостающих параметров.
Анализ диапазонов входных параметров информационных блоков, пригодных для продолжения поиска, позволяет корректировать допустимые диапазоны ввода (рис. 5).

Ясно, что для формирования диапазонов допустимых значений должны использоваться только блоки, подходящие по уже известным входным параметрам. С объединением диапазонов могут возникнуть проблемы.
С текстовыми параметрами проблем быть не должно и надо просто объединить и упорядочить списки значений (рис. 5, а). С числовыми параметрами дело обстоит сложнее (рис. 5, в, г, д). Допустимые значения числовых параметров могут быть списками, закрытыми и открытыми диапазонами. При слиянии диапазонов исключаемая граница диапазона может попасть внутрь другого диапазона или не все элементы списка попадут внутрь диапазона (рис. 5, в). Пропуски возможных значений (рис. 5, г) и неоднородность допустимых значений (рис. 5, д). Возникновение подобных ситуаций – повод озаботиться качеством информационного наполнения. Как частный обходной, но не лучший вариант, списки и диапазоны могут быть объединены, если все элементы списка попадают внутрь диапазона.
Разобраться в том, как правильно задавать области допустимых значений параметров довольно сложная задача. Для её решения требуется доскональное знание предмета. Возможно, здесь будет уместно использовать нейросетевые модели. В том числе, модель должна быть обучена анализировать табулированную информацию, поскольку числовые зависимости часто представлены разного рода таблицами.
Варианты ввода данных в диалоге
Последовательность запроса недостающих параметров в диалоге должна соответствовать важности и значимости параметров в словаре (см. рис. 3, в).
После получения очередного недостающего значения поиск следует сразу продолжить, при необходимости выполняя небольшой откат. Новое значение изменяет контекст, и какие-то блоки перестанут удовлетворять условиям применимости, что повлечёт за собой их исключение из рассмотрения.
Иногда возможен ввод значений сразу нескольких недостающих параметров. Например, если блоки имеют идентичные по составу списки входных параметров, и области допустимых значений всех параметров, кроме одного, совпадают. Или при выполнении завершающего и единственного блока, участвующего в процессе поиска решений.
Возможно ли обойтись без диалога?
Обойтись без диалога означает, что все необходимые параметры будут задаваться одновременно через форму запроса. В качестве примера можно привести задачи, напоминающие по своему составу базы данных. Выполняется поиск записей по фиксированному набору атрибутов. Гарантированно найдётся подходящий для выполнения блок или не найдётся ничего.
Так же без диалога можно обойтись, используя формы запросов, когда фиксированного набора входных параметров, при любом раскладе, будет достаточно для получения решения. Последовательности выполнения блоков могут существенно разниться, но наперёд заданных входных данных всегда будет хватать.
Анализ прикладных задач и опыт эксплуатации показывают, что вышеперечисленные варианты крайне редки. Возможность и целесообразность вводить данные однократно по фиксированным формам скорее исключение, чем правило. Зато комбинировать частичный ввод по фиксированным формам и дальнейшее продолжение ввода в диалоге – идея хорошая.
Репозитории информационных блоков
В процессе поиска решений формируются репозиторий информационных блоков. В частности, в репозиторий отправляются блоки, которые не могут быть выполнены ни при каких условиях. Это блоки, не подходящие по контексту значений заданных или промежуточных параметров. Такие блоки исключаются из процессов поиска решений.
Выполненные блоки так же отправляются в отдельный репозиторий, чтобы не мешать дальнейшему поиску решений.
Ближайшие связи информационных блоков. Самообучение системы
В простейшем варианте поиска решений информационные блоки проверяются на возможность выполнения последовательным перебором. Последовательность перебора задаётся важностью и значимостью параметров, определяемых в блоках.
Можно предложить более осмысленный вариант управления последовательностью выбора очередного блока для проверки возможности его выполнения. Очевидно, что объективно существуют условно постоянные связи между блоками. С каждым информационным блоком можно связать список блоков, которые непосредственно предшествовали его успешному выполнению. И связать список блоков, которые он успешно обеспечил данными для продолжения поиска. Если накапливать и сохранять эту информацию от запроса к запросу и использовать её, поиск решений значительно упростится (рис. 6).

В простейшем случае, такие связи можно отследить без выполнения блоков и построить соответствующий граф. В сложных случаях и условиях внесения изменений в информационное наполнение построить граф будет проблематично. Как альтернативу целесообразно запускать автоматический поиск решений. Последовательный перебор комбинаций значений входных параметров естественным путём тренирует систему. Позволяет выявлять и запоминать ближайшие связи. Автоматическая тренировка помогает обнаруживать тупиковые комбинации значений входных параметров. Уточнять диапазоны допустимых значений. Представить отчет о возникших проблемах и тем самым способствовать улучшению качества системы.
Повторное использование информационных блоков. Циклы
Если один и тот же параметр присутствует и в списке входных и в списке выходных параметров (рис. 7, блок В19), то такой информационный блок является источником циклических процессов.

Переопределение параметра (рис. 7, параметр 33), влечёт за собой необходимость сбросить признаки определения всех параметров, которые зависели от переопределённого параметра (рис. 7, параметры 31, 32). Так же должны быть возвращены из репозитория все блоки (рис. 7, блоки В17 и В18.1), участвовавшие в определении таких параметров. Возможно, изменившийся контекст задачи приведет к возврату из репозитория и выполнению блоков, которые ранее не могли быть использованы ни при каких условиях (рис. 7, блок В18.2).
Существует опасность зацикливания, предотвратить которую можно явным указанием количества возможных циклов. Неявно количество циклов ограничивается допустимыми значениями изменяемого параметра. Значения изменяемого параметра после очередного шага итерации окажутся вне допустимых границ и цикл прервётся.
Сколько выходных параметров можно определить в одном информационном блоке
Самым логичным с точки зрения ограничения избыточности порождаемых данных будет принцип "один информационный блок – один выходной параметр". Однако на практике один набор входных параметров может использоваться для определения сразу нескольких выходных параметров. Возникает ситуация избыточности контекста, которая может привести к лишним манипуляциям с зависимыми информационными блоками или, даже, к нарушению логики принятия решения.
Простым выходом может стать многократное выполнение одного и того же блока, с определением каждый раз только одного выходного параметра. Надо только позаботиться, чтобы блок не попал в репозиторий выполненных блоков до исчерпания всех возможных применений.
С другой стороны, нельзя исключать и положительного влияния на эффективность поиска решений, когда в одном информационном блоке сразу определяются несколько выходных параметров.
В каждом отдельном случае предметный специалист должен ответить на вопрос целесообразно или нет, сразу определять несколько выходных параметров.
По завершении успешного поиска решений могут остаться параметры, которые нигде не потребовались и не использовались. Это повод внести коррективы в информационное наполнение. Скорее всего, какие-то информационные блоки породили невостребованные результаты.
История поиска
По аналогии с шахматами логично предположить, что поиск решений, хотя бы в самом начале, будет выполняться одним и тем же "дебютным" путём. Раз за разом будет повторяться последовательность использования одних и тех же информационных блоков. Этим стоит воспользоваться для оптимизации процесса поиска решений. Попытаться повторить последовательность предыдущего поиска до первого неудачного применения блока из сохранённой последовательности.
Начальный выбор
Для однотипных задач, диалог обычно, начинается с запроса одних и тех же параметров. Если запомнить этот начальный выбор, можно значительно сократить перебор блоков в самом начале поиска.
Сопровождение
Известно, что головной болью сопровождения прикладного программного обеспечения является изменчивость предметной области: потребность в оперативной корректировке алгоритмов и устранении обнаруженных в ходе тестирования и эксплуатации ошибок.
Когда система базируется на относительно независимых функциональных единицах (информационных блоках) и управляется динамически порождаемыми данными (нет жесткого алгоритма), процесс сопровождения значительно упрощается. Внесение изменений в информационные блоки и словарь не критично. Могут быть слегка затронуты интерфейсы взаимодействия с конечным пользователем в части последовательности ввода данных. При незначительных корректировках конечный пользователь вообще ничего не заметит. Изменения получится вносить, не останавливая работу системы. Более серьёзные изменения обеспечит смена версий. Но опять же, кардинальных изменений для конечного пользователя не случится. Замена версии это просто замена изменённых информационных блоков, добавление новых блоков и удаление более не нужных блоков. А так же изменение словаря и автоматическое распространение исправлений по затронутым изменениями информационным блокам.
Блок-схема возможной организации процесса поиска решений

Псевдокод возможной реализации поиска решений

Заключение
Вышеописанные подходы к реализации поиска решений управляемого данными позволяют подойти к созданию сложных (для классического программирования) систем относительно простыми средствами. В каком-то смысле это no-code для многовариантных задач прикладного назначения.
Вероятно, будут предложения воспользоваться теорией графов, но преобразовать в граф структуру информационных блоков весьма сложная и ресурсоёмкая задача. К тому же при внесении изменений потребуется каждый раз перестраивать граф.
Рассматриваемое в статье решение обеспечивает динамическое связывание информационных блоков без привлечения сложного математического аппарата, весьма простым и понятным для прикладных специалистов способом.
Важно, что диалоговый ввод недостающих данных обеспечивает получение результата за один проход. В этом коренное отличие от нейросетевых моделей, когда уточнение задачи обычно возможно только после полного завершения генерации ответа.
Поиск решений управляемый данными, как было представлено выше, не требователен к вычислительным ресурсам и легко реализуем известными штатными средствами.
Источник
Вам также может быть интересно

Лучшие криптовалюты для покупки во время обвала рынка: выделяются BlockDAG, SOL, Ondo Finance и Render

Акции Sony Group Corporation (SONY): расширение программы обратного выкупа после рекордных результатов третьего квартала
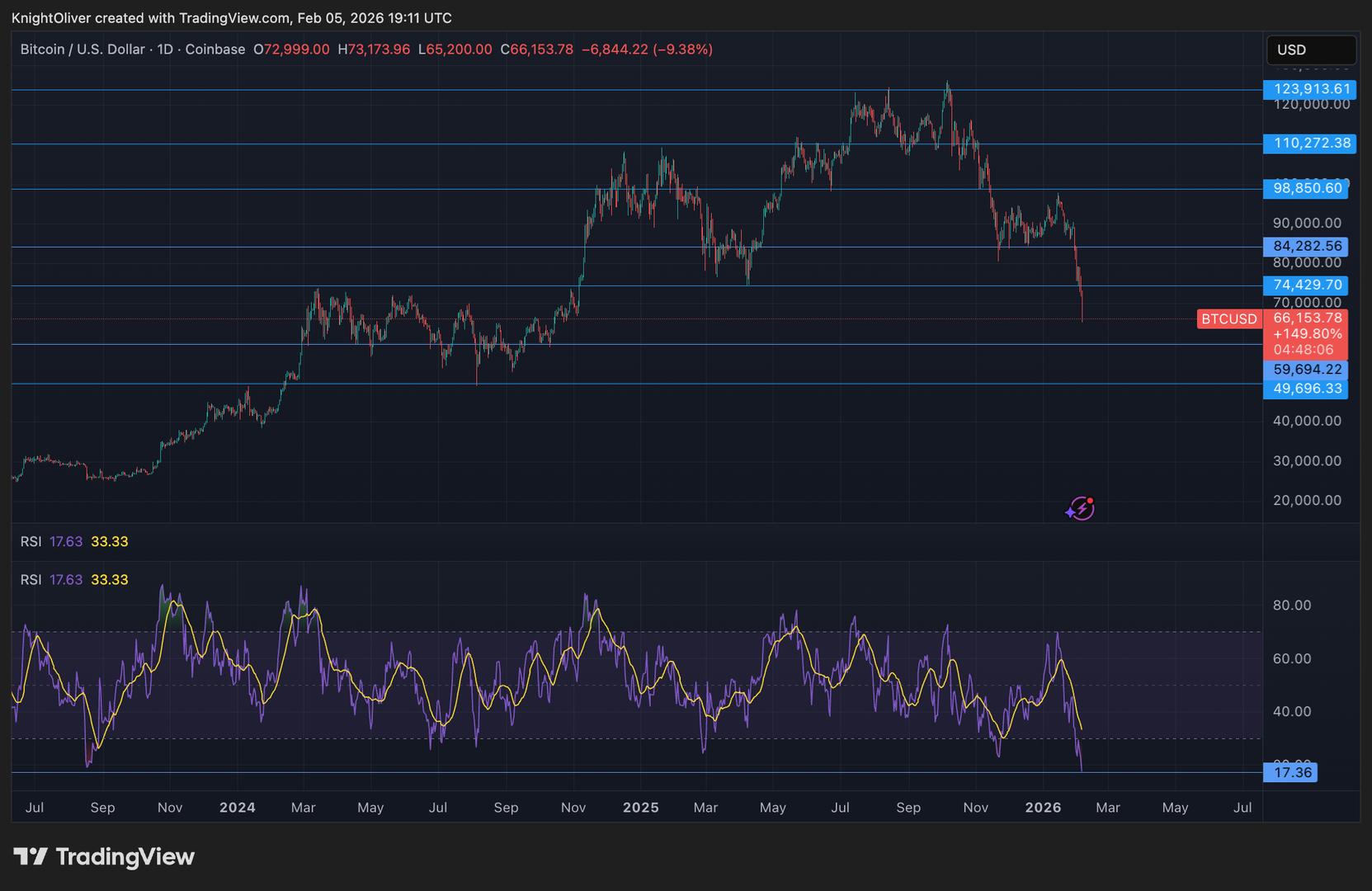
Биткоин третий самый перепроданный за всю историю, говорит один индикатор, и резкий рост может быть следующим
Рынки
Поделиться
Поделиться этой статьёй
Скопировать ссылкуX (Twitter)LinkedInFacebookEmail
Bitcoin третий по перепроданности за всё время, говорят