

CZ publicly recommends the AI data track. How does OORT start the commercial narrative through DeAI?
Author: Nancy, PANews
Once upon a time, software devoured the world. Today, AI is devouring software. Standing on the long river of technological progress, the revolutionary picture around the AI big model is rapidly unfolding and opening up new application space at an astonishing speed.
Some time ago, when talking about AI, Binance founder CZ pointed out that "AI labeling and data processing are very suitable to be completed on the chain, realizing instant (micro) payments through cryptocurrencies, while utilizing low-cost labor around the world without geographical restrictions." This view has added fuel to the already hot crypto AI track, and has also led to crypto projects such as OORT that have released related products to once again become the focus of the market.
Funded by giants such as Microsoft and Google, OORT is a pioneer in the field of decentralized AI. It creates a decentralized trust infrastructure for the AI era. While realizing commercial applications, it promotes the democratization and popularization of AI development processes through innovative DeAI (decentralized artificial intelligence) solutions.
From data, storage to computing, OORT's three flagship products unlock the potential of AI
Since ChatGPT set off a wave of AI big models, major technology giants have been competing to "make" models, and the market has once presented a "hundred-model war" situation. At present, "data" has become a must-have for AI big model training, because the publicly available data worldwide has been exhausted.
For all companies around the world, data collection, storage and processing, especially the acquisition and labeling of high-quality data, have reached a bottleneck in their development. Traditional centralized cloud service providers usually rely on high-cost and monopolistic data collection models, and often lack transparency and trust, which has brought many restrictions to the training and application of AI models, and also triggered a series of concerns about compliance and ethics.
"One of the most pressing issues facing AI is the 'black box' dilemma, where the AI decision-making process is opaque and difficult to audit. Blockchain's immutable and transparent ledger provides a powerful solution, recording every stage of the AI lifecycle, from data collection and training to deployment decisions. This ensures that the system can be audited and remains trustworthy. By integrating blockchain technology into AI development, transparency can be ensured, ethical guidelines can be enforced, and monopoly control can be prevented," said Dr. Max Li, founder and CEO of OORT. "DeAI proposes an AI development model that everyone can participate in, from development to deployment, creating a decentralized AI alternative to challenge centralized AI companies like OpenAI."
In response to the "data black box" problem in the AI field, OORT combines AI and DePIN services, not only improving the transparency and traceability of data through blockchain technology, but also using effective economic incentives to encourage more users to participate and contribute, ensuring the high quality and real-time nature of data, thereby promoting the further implementation and popularization of AI technology applications.
OORT has three flagship products, namely decentralized object storage solution (OORT Storage), decentralized artificial intelligence data collection and annotation (OORT DataHub), and decentralized computing service (OORT Compute, the commercial version has not yet been officially launched). These three products provide innovative decentralized solutions to the pain points of data storage, data collection and annotation, and computing services.
Among them, CZ publicly advocated the idea of using blockchain to realize AI data annotation, and OORT has taken the lead in exploring the implementation through OORT DataHub. OORT DataHub is OORT's second commercial product and the world's first decentralized data collection and annotation solution. It can provide decentralized AI data collection and annotation services for developers, enterprises and researchers, and the commercial version has been officially launched.
As we all know, the success of AI requires a large amount of data to learn, especially high-quality data sets are an important factor in improving the performance and decision-making ability of AI models. However, data annotation and collection generally have problems such as uneven quality and high costs. OORT DataHub provides reliable and traceable data, while breaking the geographical limitations of traditional platforms, allowing users around the world to contribute data such as images, audio or video through the DataHub platform to improve AI and machine learning models.
At the same time, in order to better motivate users to participate and contribute data, OORT DataHub has introduced a mechanism to pay global contributors in cryptocurrency. The mechanism starts with points. Contributors can earn points by logging in daily, completing tasks, verifying tasks, and recommending, thereby unlocking USDT rewards - this is the fundamental bottleneck that traditional data collection cannot achieve truly global data collection, because the traditional banking system cannot effectively implement global cross-border micropayments. In addition, OORT DataHub also introduces NFT as an additional reward mechanism to share the right to income from future data sales. It is worth mentioning that in order to promote product adoption on a large scale, OORT has launched the OORT DataHub mini application to achieve seamless integration with Telegram.
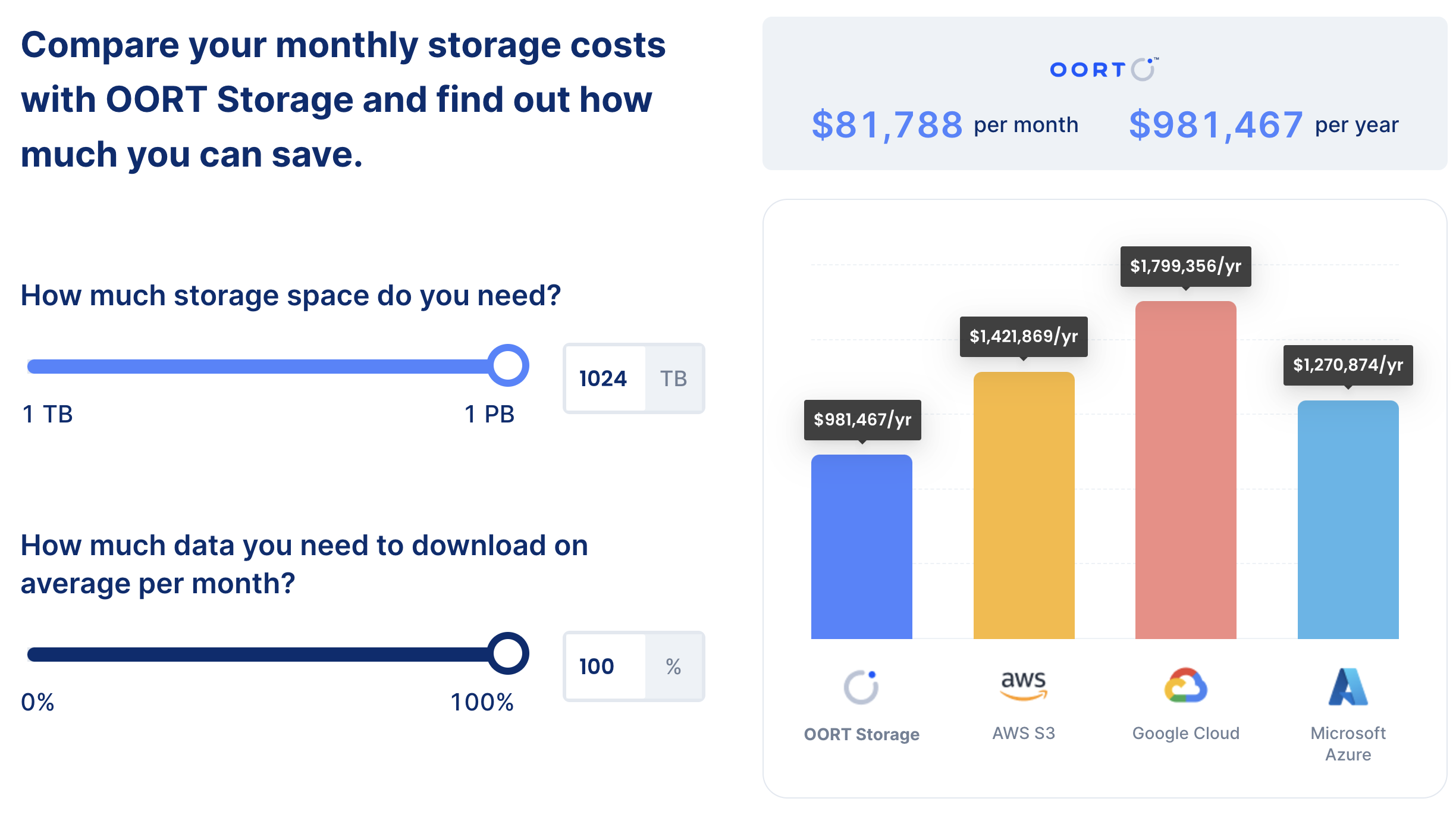
OORT Storage can provide secure storage and management of hot and cold data. In addition to meeting enterprise-level availability, durability, and latency requirements, as well as integrating AI to easily achieve data interaction, it also provides on-demand billing services that are up to 80% cheaper than traditional giants such as AWS. Not only that, in order to enhance the privacy protection of user data, OORT has adopted a decentralized data infrastructure to implement data management, which can effectively resist censorship and single points of failure. Currently, OORT Storage already supports links to popular storage management tools such as ChatGPT, AWS CLI, Rclone, and S3 Browser.
OORT Compute, which has not yet been officially launched, is a decentralized computing service with the advantages of low cost, high privacy and easy access. It can realize decentralized data analysis and processing (such as training and fine-tuning of large models) by integrating global GPU resources. The product has not yet been officially launched.
In this process, in order to ensure the reliability and availability of data and realize the globalization of the DeAI ecological network, OORT's cloud infrastructure layer adopts a three-layer node architecture, including super nodes such as Tencent Cloud and SEAGATE, backup nodes such as Filecoin, Storj and Arweave, and edge nodes composed of personal devices. As of now, OORT's network nodes have exceeded 65,000.
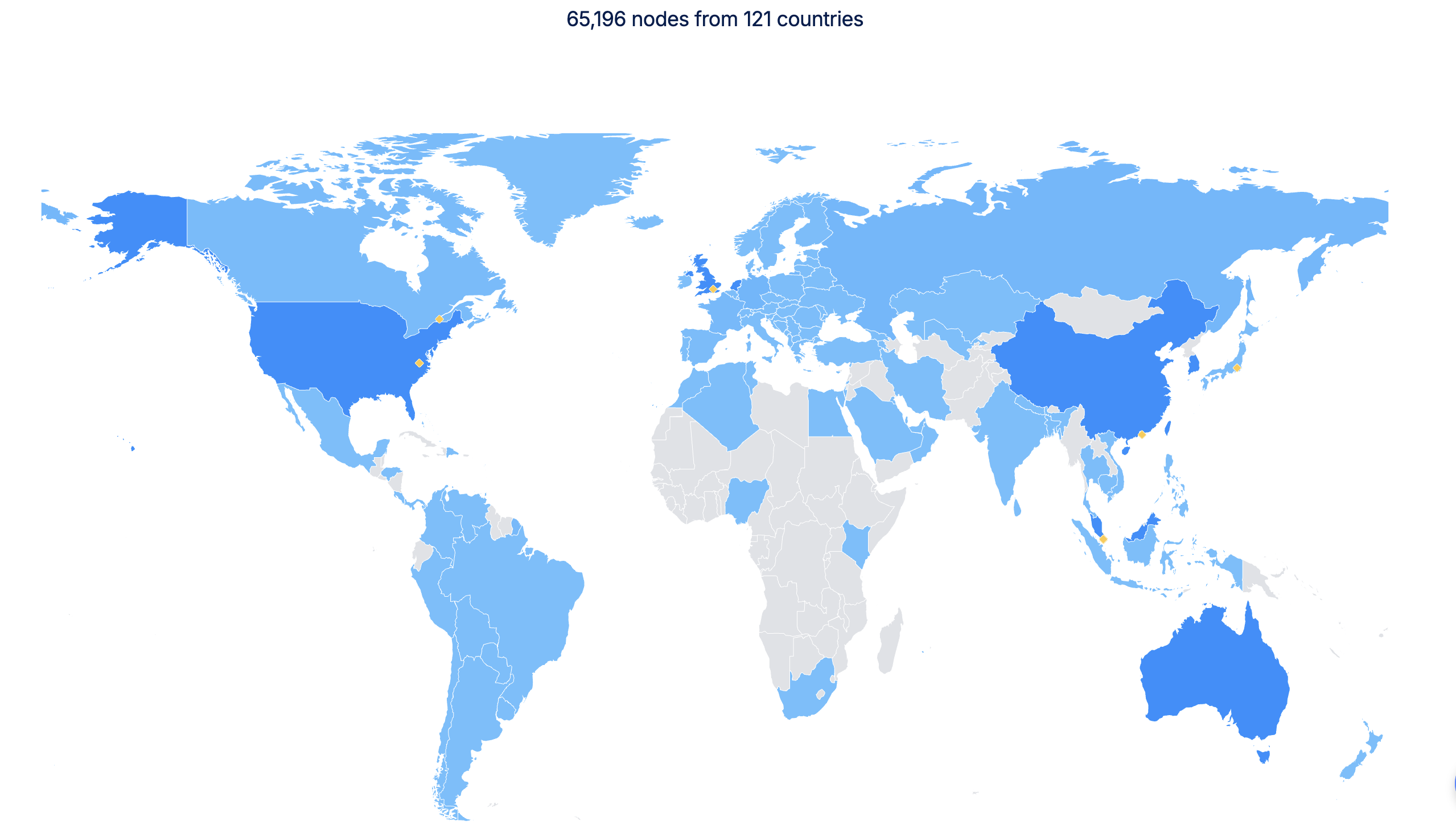
From this point of view, OORT can not only effectively solve the pain points of the AI industry in data collection, storage and processing, but also reduce data collection and computing costs through a decentralized mechanism, providing strong infrastructure support for the development of AI.
Technological exploration in the commercial context, academic achievements stepping out of the "ivory tower"
Past experience tells us that every new technology must go through the transition from infrastructure construction to commercial implementation, otherwise it will be difficult to form a real competitive moat. OORT is also continuously advancing the "monetization" of DeAI technology. Through effective commercialization paths, it not only builds its own advantages, but also promotes the application of AI technology in various industries.
For example, the global loyalty program of technology giant Dell has integrated OORT Storage business, which can provide Dell customers with decentralized storage services, including data storage and migration; OORT has signed a three-year contract with Lenovo, achieving 40% cost savings and 95% customer satisfaction rate through its customized AI assistant; Tencent Cloud has become a full node provider of the OORT network, and applications deployed on the former's data cloud can obtain more comprehensive data services and enhance their privacy and security; OORT provides storage support for BNB Greenfield and ensures privacy and cost-effectiveness; OORT cooperates with the eCAT IUCRC Research Center of the National Science Foundation of the United States to improve the safety and efficiency of electric, connected and autonomous vehicles, etc.
The reason behind OORT's successful commercialization was not to chase a short-term market boom, but rather to meet the actual needs of an academic challenge. As early as 2018, Dr. Max Li, founder and CEO of OORT, encountered a problem when teaching an artificial intelligence course at Columbia University. When his graduate students were working on a project that required training an AI agent, they found that traditional cloud computing services (such as Amazon AWS and Google Cloud) were too expensive for students and far exceeded their budget. This problem inspired Max to think deeply about how to optimize cloud computing costs through blockchain technology, which not only helped students successfully complete the project, but also laid the foundation for the birth of OORT.
Max's profound academic and technical background also laid a solid foundation for OORT to step out of the academic "ivory tower". As an experienced technology industry expert, he worked as a researcher at Qualcomm Research Institute and participated in the design of 4G LTE and 5G systems. He is also a prolific inventor and technical expert, holding more than 200 international and US patents covering multiple fields, especially in communications and machine learning. The other core team members of OORT are also very capable, and their members mainly come from world-renowned institutions such as Columbia University, Qualcomm, AT&T, and JPMorgan Chase.
With solid technical accumulation, strong team strength, successful commercial products and clear market positioning, OORT has also been highly recognized by the capital market and received nearly $10 million in financing this year. Investors include Taisu Ventures, Red Beard Ventures, Hike Ventures and Optic Capital, as well as support from technology giants Microsoft and Google. In Max's view, 2025 will be the year when decentralized AI will move from a niche to commercialization and implementation. The integration of blockchain and AI will gradually become mainstream, which will have a profound impact on the development in the next few decades.
In short, as a hot potential stock in the DeAI field, OORT's continued commercialization not only reflects its transformation of technical strength based on actual commercial needs, but also reveals the huge market potential in the DeAI field, which will inject more impetus into the popularization and advancement of AI technology.


Ayrıca Şunları da Beğenebilirsiniz

Siren (SIREN) Plunges 29.9% as Trading Volume Surges 800% Amid Market Correction

Tokenization Value Hinges on Liquidity, Not Novelty



